Que vous soyez un CTO, un CEO, un porteur de projet ambitieux ou bien un développeur, l’idée d’explorer les possibilités du ML dans le domaine de l’informatique embarquée peut sembler aussi intrigante que complexe.
Dans cet article, nous vous invitons à plonger dans l’univers du machine learning appliqué à l’environnement embarqué, où la convergence de l’intelligence artificielle et des systèmes embarqués ouvre la voie à des avancées majeures.
Explorez avec nous les possibilités qui se présentent !
Quelle est la différence entre l’IA et le machine learning ?
Avant de plonger dans les applications concrètes du ML dans le domaine de l’informatique embarquée, faisons un bref retour sur les bases du machine learning et de l’intelligence artificielle.
L’intelligence artificielle (IA) et le Machine learning (ML) sont des domaines en constante évolution qui ont suscité un intérêt croissant ces dernières années.
Le machine learning représente une branche de l’IA et permet aux systèmes informatiques d’apprendre et de s’améliorer à partir du combo expérience plus résultats attendus, sans être explicitement programmés.
En d’autres termes, au lieu de programmer des règles spécifiques, on expose le système à des données puis celui-ci tire des conclusions de manière autonome.
Tandis que l’intelligence artificielle englobe un ensemble plus large de technologies visant à doter les machines de la capacité à simuler l’intelligence humaine.
Alors, comment ces concepts abstraits se traduisent-ils dans le domaine concret de l’embarqué ? Comment l’IA peut-elle s’intégrer harmonieusement dans des systèmes limités en termes de ressources, d’énergie et de connectivité ?
C’est ce que nous allons explorer dans cet article en mettant en lumière des applications concrètes qui démontrent la puissance du machine learning dans des situations réelles de l’informatique embarquée.
Découvrons comment l’IA devient un véritable catalyseur d’innovation, ouvrant de nouvelles perspectives passionnantes pour des projets ambitieux et innovants.
L’IA dans l’embarqué, c’est pour quoi faire ?
Maintenant que nous avons défini IA et machine learning, plongeons dans les applications de l’IA embarquée avec des scénarios concrets qui démontrent son potentiel transformateur.
Ces applications pratiques ne représentent qu’un échantillon des possibilités que l’IA embarquée peut offrir.
En se focalisant sur des applications telles que la reconnaissance de mouvement, de type de sol, les interfaces homme-machine audio, et le retrofit d’objets existants sans oublier le contrôle de glycémie automatique et la maintenance prédictive, nous étudierons comment l’IA embarquée redéfinit les règles du jeu dans des secteurs variés.
Reconnaissance de mouvement : détection de chute, tracking de nage

L’Apple Watch, en plus de ses fonctionnalités traditionnelles, est capable de détecter les chutes et d’appeler les services d’urgence si nécessaire. Il faut savoir que plus d’un tiers des personnes de plus de 65 ans tombent chaque année aux États-Unis, cette fonctionnalité a donc le potentiel d’aider une partie importante de la population.
Pour détecter les chutes, l’Apple Watch utilise un mécanisme similaire à celui qu’elle emploie pour suivre la natation. Elle utilise son accéléromètre et son gyroscope pour différencier les types de mouvements, comme les différentes nages en natation. Pour développer cette fonctionnalité, Apple a collecté des données auprès de centaines de nageurs et a utilisé des données réelles de chutes pour entraîner ses modèles de machine learning.
Ces données ont aidé à distinguer les mouvements normaux des chutes. Jeff Williams, Chief Operating Officer chez Apple, explique que les chutes présentent des modèles de mouvements reconnaissables, comme le mouvement involontaire des bras pour se protéger lorsqu’on tombe.
Pour en savoir plus, nous vous recommandons ces deux articles détaillés sur la détection de chute et le suivi de nage de l’Apple watch.
Enfin, pour se faire une idée de comment réaliser ce genre de projet et quels résultats on peut obtenir en partant de zéro, STMicroelectonics a réalisé une démonstration de reconnaissance d’activité basée sur un accéléromètre et un gyroscope. Résultat : 96% de précision sur la détection de 5 activités (marche, montée d’escalier, descente, etc.), avec un modèle qui rentre aisément sur un microcontrôleur grâce à seulement 6.7 Ko de RAM et 15.2 Ko de Flash utilisées.
Reconnaissance de scène
Pour améliorer l’efficacité d’un robot aspirateur, un système de détection du type de sol a été développé dans ce projet par STMicroelectronics.

L’objectif est simple : optimiser l’efficacité du robot aspirateur en lui permettant d’adapter son mode de nettoyage en fonction de la surface à traiter.
Au cœur de cette avancée technologique, on retrouve le capteur de temps de vol VL53L5CX, stratégiquement positionné sur le robot nettoyeur.
La matrice de distances mesurées par ce capteur constitue l’entrée d’un réseau neuronal dédié à la reconnaissance du type de sol. Ce modèle, préalablement entraîné sur une variété de matériaux, est intégré sur un microcontrôleur à l’aide des outils de la suite STM32Cube.AI.
Comparée à la programmation conventionnelle, cette approche centrée sur l’IA offre des améliorations notables en termes de précision, pouvant atteindre jusqu’à 96 % sur divers types de sols.
Les performances reportées par ST Microelectronics dans ce projet sont les suivantes :
- Empreinte mémoire : 68 Ko pour les paramètres de poids du réseau neuronal, et 1.6 Ko pour les activations
- Précision : 96 % sur plus de 50 types de matériaux, soit environ 200 000 échantillons.
- Performances sur STM32F401 à 84 MHz : Temps d’inférence de seulement 7 ms
Cette avancée dans la détection du type de sol marque un progrès significatif dans le domaine des robots aspirateurs, offrant une approche plus intelligente et réactive à l’environnement.
Interface homme-machine audio
Les interfaces homme-machine vocales ont révolutionné la manière dont nous interagissons avec nos objets connectés, offrant une alternative naturelle aux boutons traditionnels et aux petits écrans.
Popularisées par des assistants virtuels tels que Hey Siri sur iPhone ou OK Google sur Android, ces interfaces peuvent désormais être intégrées sur des microcontrôleurs et customisées aux besoins de son application.
C’est ce que propose NXP avec sa plateforme gratuite Voice Intelligent Technology.
Elle propose un portail en ligne no code pour créer une application de commande vocale personnalisée, pouvant fonctionner sur des micro-contrôleurs NXP.
VIT Tool, permet aussi de créer rapidement des applications wake word, qui écoutent en permanence le flux audio dans l’attente d’un mot pré-défini, un wake word.
Autre exemple : l’entreprise Sensory Inc. propose le même type de service que NXP avec sa plateforme VoiceHub, qui peut cibler des MCU comme le STM32H7.
Retrofit d’objet existant : l’IA embarquée au service de l’innovation

Le marché du retrofit, également appelé aftermarket, offre la possibilité de moderniser des objets électroniques existants en ajoutant des modules électroniques pour leur fournir de nouvelles fonctionnalités.
Concrètement, ça veut dire quoi ?
Prenons l’exemple de la conversion d’un compteur d’électricité ou de gaz traditionnel en un compteur connecté.
ST Microelectronics a développé un module de reconnaissance de chiffre accompagné d’une connectivité sans fil, qui s’intègre au-dessus du compteur traditionnel.
La reconnaissance de chiffre en environnement maîtrisé est une tâche idéale pour de l’IA embarquée car elle se base sur un réseau de neurones plutôt léger.
Les performances rapportée par ST Microelectronics pour un tel projet sont les suivantes :
- Empreinte mémoire : 148 KB de Flash pour les paramètres de poids du réseau de neurones, 57 KB de RAM pour les activations.
- Sur un microcontrôleur STM32L462 (Low Power) cadencé à 80 MHz, le temps d’inférence pour la reconnaissance de 8 chiffres est de 900 ms.
Cette démonstration souligne le potentiel de l’IA embarquée dans le retrofit pour permettre des améliorations significatives sur tous types d’équipement existants et ouvrir la voie à de nouvelles applications innovantes.
Contrôle de glycémie automatique : les avantages de l’IA embarquée offline
Diabeloop est une entreprise française qui développe, en partenariat avec le CEA-Leti, des produits pour automatiser le traitement du diabète de type 1.
Son premier produit, le système DBLG1, est un système intégré qui permet un contrôle glycémique automatique.
Le cœur de cette innovation est une Intelligence Artificielle hébergée sur un terminal qui se connecte via Bluetooth à un capteur de glucose en continu (CGM) et à une pompe à insuline. L’algorithme prend et exécute les nombreuses décisions thérapeutiques que les patients doivent actuellement gérer eux-mêmes.
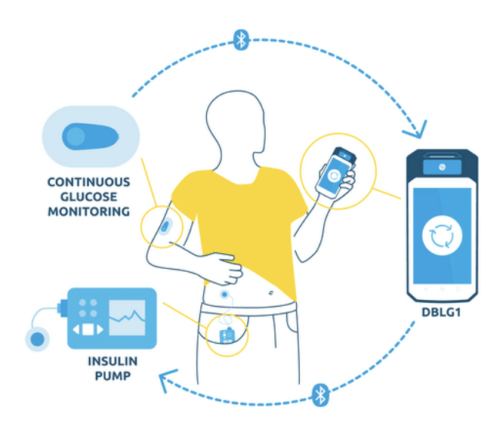
Toutes les 5 minutes, une mesure de glucose est transmise en Bluetooth au DBLG1. L’intelligence artificielle analyse les données en temps réel, tout en tenant compte de la physiologie, de l’historique et des saisies de données (repas ou exercice) du patient pour déterminer la bonne dose d’insuline à administrer.
L’IA embarquée apporte tout son lot d’avantages par rapport à une solution cloud et non-embarquée :
- Le système est autonome, il n’a pas besoin d’une connexion internet pour fonctionner, donc pas de risque d’arrêt du contrôle glycémique en cas de perte de réseau.
- La confidentialité des données de santé est grandement renforcée, car ces données restent en local; elles ne sont pas envoyées sur des serveurs pour être analysées.
- La faible puissance requise pour exécuter l’algorithme permet de l’intégrer sur un équipement portable, et de mettre le système dans sa poche pour l’avoir avec soi peu importe où que l’on soit.
Maintenance Prédictive

Le Bob Assistant, de NKE Watteco
Parmi toutes les applications de l’IA embarquée, la maintenance prédictive se démarque car c’est l’une des plus répandues, exploitant des analyses avancées des données de capteurs, pour anticiper les défaillances à l’aide de modèles de machine learning.
Prenons l’exemple d’une application commerciale publiée par notre partenaire ST Microelectronics dans laquelle l’analyse des vibrations des rails ferroviaires par Vapérail permet une détection précise et minutieuse des dysfonctionnements.
Cette approche génère une alerte instantanée à destination des équipes de maintenance, leur offrant la possibilité d’intervenir rapidement et de vérifier la présence réelle du défaut identifié.
Cette capacité à anticiper les pannes s’avère cruciale, car elle permet d’identifier des anomalies avant qu’elles ne se transforment en défaut majeurs, pouvant parfois avoir des conséquences désastreuses.
Passons ensuite à un autre secteur : celui du transport de fluides.
Découvrons la preuve de concept d’un hobbyiste qui s’est donné pour objectif de créer un système de surveillance des réseaux d’oléoducs, alliant efficacité et rentabilité pour un déploiement à grande échelle.
En effet, ces réseaux s’étendent sur de vastes distances et représentent des milliers de km d’infrastructure à surveiller.
Basé sur un capteur radar millimétrique à 60 GHz, ce système mesure les vibrations fines des conduits provoquées par le passage du fluide. Ces mesures sont ensuite données en entrée d’un réseau de neurone développé avec l’outil d’IA Edge Impulse, pour détecter les fissures, les obstructions, et les fuites présentes sur les conduits.
L’intérêt de l’IA embarquée est particulièrement évident dans ce cas.
Elle permet :
- La détection de motifs dans les signaux bruts du radar, révélant des défauts invisibles à l’œil nu tels que fissures, ou obstructions.
- La possibilité de surveiller de nombreux points de l’installation, parfois situés dans des zones reculées, grâce à un système économique en énergie. Cela favorise un déploiement à grande échelle dans des zones soumises à des contraintes de connectivité et de disponibilité énergétique.
Au-delà de ces exemples, il existe une multitude d’autres applications de maintenance prédictive exploitant le machine learning (nke Watteco, Oxytronic, etc.).
Elles se basent sur une diversité de signaux, incluant des grandeurs électriques (courant, tension), des données audio, ou des caractéristiques vibratoires, entre autres.

IRMA, la solution de maintenance prédictive d’Oxytronic
L’IA dans l’embarqué, quel coût pour mon projet ?
Développement et intégration du machine learning
Tout d’abord, dès lors qu’on intègre à son produit un algorithme d’apprentissage automatique, celui-ci aura deux grandes phases de vie :
- La mise en place d’un algorithme
- Son monitoring et sa maintenance.
En effet, davantage encore que pour un produit électronique traditionnel, « après le premier déploiement de votre produit sur le terrain vous n’êtes peut-être qu’à mi-chemin de l’objectif. Un travail considérable reste à faire en matière de surveillance et de maintenance du système » (Andrew Ng, fondateur de LandingAI et DeepLearning.AI). En voici les deux raisons principales d’après Andrew Ng :
- Dérive de données : Votre modèle a été entraîné avec un certain jeu de données, mais les données entrantes peuvent changer avec le temps. Par exemple, un modèle peut avoir appris à estimer la demande d’électricité à partir de données historiques, mais le changement climatique provoque des changements météorologiques sans précédent, de sorte que la précision du modèle se dégrade.
- Dérive conceptuelle. Le modèle a été entraîné pour apprendre une cartographie x->y, mais la relation statistique entre x et y change, de sorte que la même entrée x exige désormais une prédiction y différente. Par exemple, un modèle qui prédit les prix des logements en fonction de leur superficie en mètres carrés perdra en précision à mesure que l’inflation entraînera une hausse des prix.
Ce qu’il faut retenir, c’est que le développement de votre produit nécessitera peut-être une charge de travail supplémentaire après les premières livraisons.
Intéressons nous maintenant à la première phase, celle du développement de l’algorithme.
Pour savoir combien coûte son développement, regardons comment il est conçu.
On considère généralement qu’il se fait en 5 grandes étapes :
1. La Collecte de données
C’est l’enregistrement ou la récupération de données brutes issues des capteurs, correspondant aux cas d’usage cibles.
Par exemple, pour détecter la défaillance d’un moteur, on pourra choisir d’utiliser un accéléromètre fixé à un endroit stratégique sur le moteur pour détecter des anomalies vibratoires. Ces données seront fournies après traitement au modèle de machine learning, pour qu’il en extrait les règles qui permettent de distinguer les informations qui nous intéressent, l’anomalie vibratoire du moteur par exemple.
2. Pré-Traitement des données
Les données brutes sont transformées pour en extraire les données utiles et les formater de manière efficace.
Cela peut inclure des étapes telles que le nettoyage des données, la normalisation, le filtrage, la création de données synthétiques qui ressemblent aux données réelles (augmentation de data), la création et l’extraction de nouvelle feature, c’est à dire d’informations caractéristiques du problème qu’on cherche à résoudre. Par exemple, le spectre des fréquences des vibrations du moteur sera probablement utile pour aider à caractériser la vibration.
3. Développement du modèle de Machine Learning
La création ou la modification d’un modèle existant, son entraînement, son optimisation.
Les choix faits ici sont issus d’un compromis entre performance de l’algorithme et ressources utilisées sur la puce cible. Cette étape complexe requiert une expertise approfondie en intelligence artificielle, notamment la contribution essentielle d’un data scientist.
4. Évaluation du modèle
Analyse de la précision, de la robustesse et de l’empreinte mémoire (RAM et Flash). Si les résultats de cette étape ne sont pas concluants, les étapes précédentes doivent être répétées.
5. Déploiement
Dans cette dernière étape, l’algorithme est converti en langage C/C++ et optimisé pour la plateforme cible.
Chacune de ces grandes étapes en regroupent en fait de nombreuses autres, exigeant chacune des décisions techniques importantes. Il y a généralement plusieurs aller-retours entre chaque étape tout au long du développement, pour affiner ou reprendre les choix faits précédemment.
Le développement complet d’un système représente donc une charge de travail très lourde, nécessitant des compétences fortes dans différents domaines.
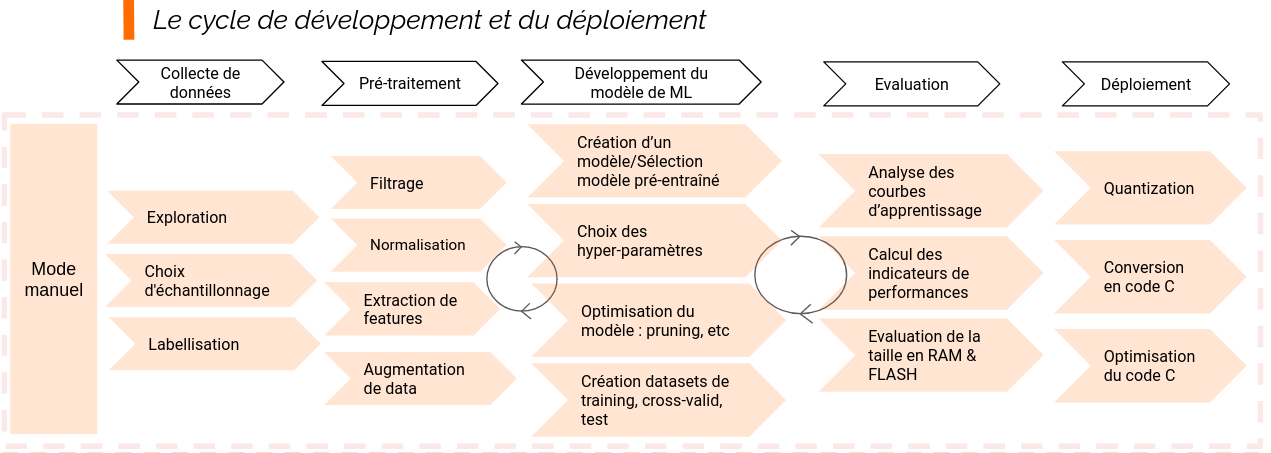
Certaines tâches comme les choix d’échantillonnage lors de la Collecte de données, ou le Filtrage dans la phase de prétraitement, demandent des connaissances en traitement du signal.
D’autres sont spécifiques au machine learning, et demandent une certaine expérience pour les aborder. Nous n’allons pas les décrire ici, mais elles sont le cœur du système, leur maîtrise permet de s’adapter à un maximum de cas d’utilisation et d’optimiser au mieux la solution.
En conclusion, pour tout faire soi-même, comme dans bien d’autres domaines, cela demanderait énormément de temps.
Mais heureusement, pour développer beaucoup plus rapidement votre produit, l’auto-ML est arrivé dans l’informatique embarquée !
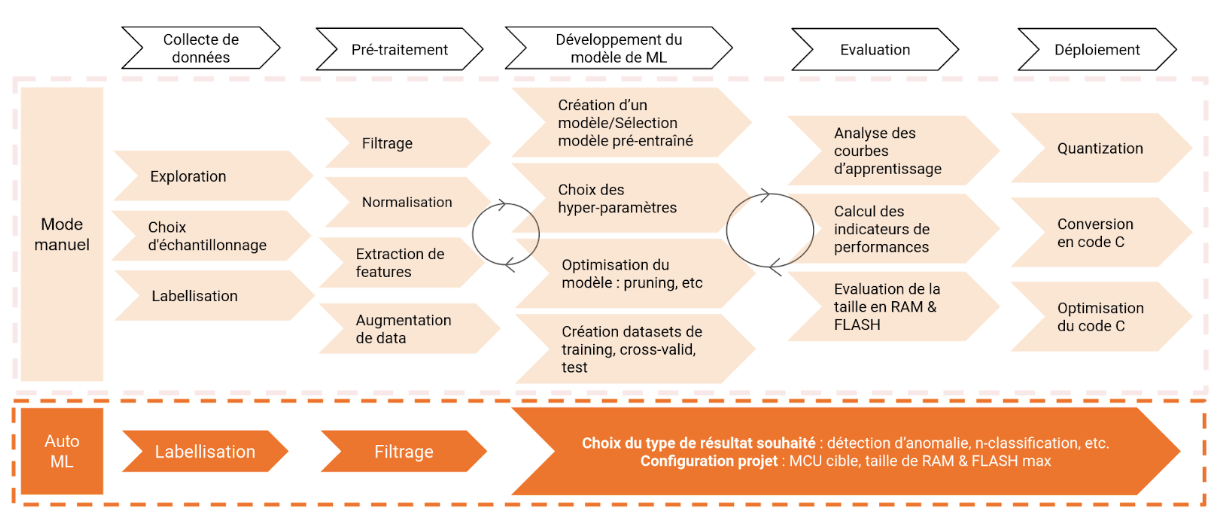
L’Auto-ML
Passons maintenant à l’apprentissage automatique d’un système de machine learning (AutoML).
Il consiste à automatiser la grande majorité des étapes de développement d’un modèle de ML, de la collecte de données au déploiement du modèle sur cible.
Certains outils d’AutoML simplifient tellement le processus qu’ils réduisent le nombre total d’étapes de travail à seulement quelques-unes !
Ce type d’outils a été conçu pour des développeurs en logiciel embarqué, sans compétence en machine learning. Il simplifie tous les aspects liés au machine learning et au traitement du signal.
Prenons l’exemple de l’outil Nano Edge AI studio de ST Microelectronics.
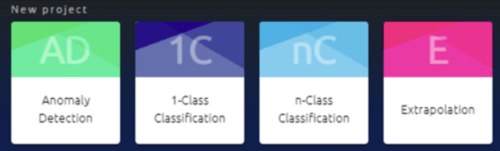
La première étape de création d’un projet consiste à choisir son type, c’est-à-dire le type de résultat attendu en sortie d’algorithme : Détection d’anomalie, Classification 1 classe, Classification de plusieurs classes, ou encore Extrapolation.
S’ajoute ensuite l’étape de configuration du projet, qui sert à définir plusieurs critères :
- La quantité max de RAM : il s’agit de la quantité maximale de mémoire RAM à allouer à la bibliothèque IA. La recherche automatique de modèle de ML tiendra compte de ce paramètre lors de la sélection du modèle, de sa conversion et de son optimisation en langage C.
- La quantité max de Flash : il s’agit de la quantité maximale de mémoire flash à allouer à la bibliothèque IA. La recherche automatique de modèles de ML tiendra également compte de ce critère.
- Le type de capteur : cela concerne le type de capteur utilisé pour collecter les données dans le projet, ainsi que le nombre d’axes/variables. Cette sélection influencera surtout l’automatisation des étapes d’échantillonnage et pré-traitement
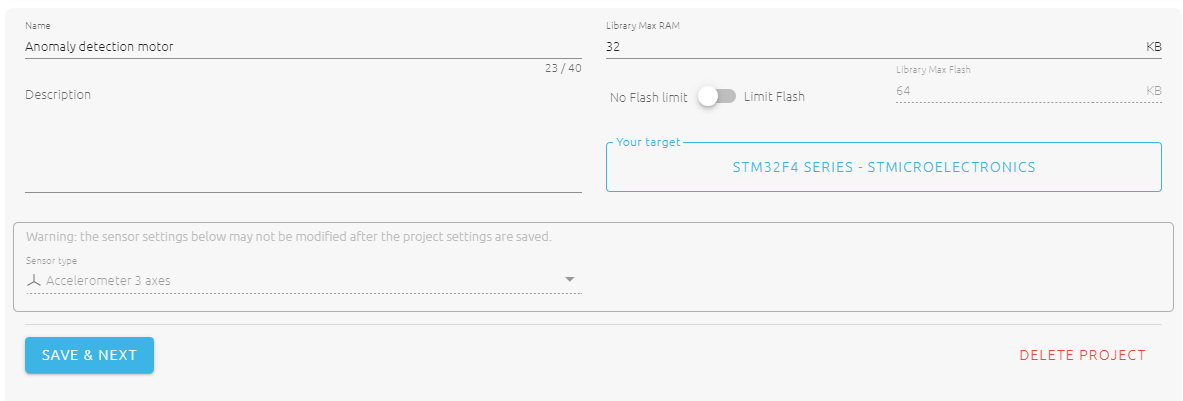
Nano edge AI studio, étape de configuration du projet
Après avoir franchi quelques étapes supplémentaires, telles que l’importation des données à utiliser, l’outil peut être exploité pour automatiser les choix d’échantillonnage. Par la suite, il agit comme un moteur de recherche qui sélectionne automatiquement les meilleurs prétraitements et le meilleur modèle de machine learning. Ce sont ceux qui donneront les meilleurs résultats sur un ensemble d’indicateurs propres au algorithmes de ML, que certains outils résument en un seul et unique score global exprimé en pourcentage.
Il réalise ensuite la conversion et l’optimisation du modèle en C/C++ pour la plateforme configurée.
Cas concret d’utilisation
Voyons maintenant un exemple concret d’utilisation du Nano Edge AI studio dans le cadre d’un projet interne chez Rtone.
Nous avions pour objectif de créer un appareil utilisant un modèle de machine learning pour détecter une anomalie vibratoire sur un ventilateur.
Explorons les différentes étapes par lesquelles nous sommes passés. Ce cheminement offre un aperçu du processus complexe de mise en œuvre de l’apprentissage automatique dans des environnements embarqués.
1. Collecte des données
Sans jeu de données pré-existant, nous avons collecté des données en programmant une carte de développement B-L475E-IOT01A pour enregistrer les données de l’accéléromètre via l’UART.
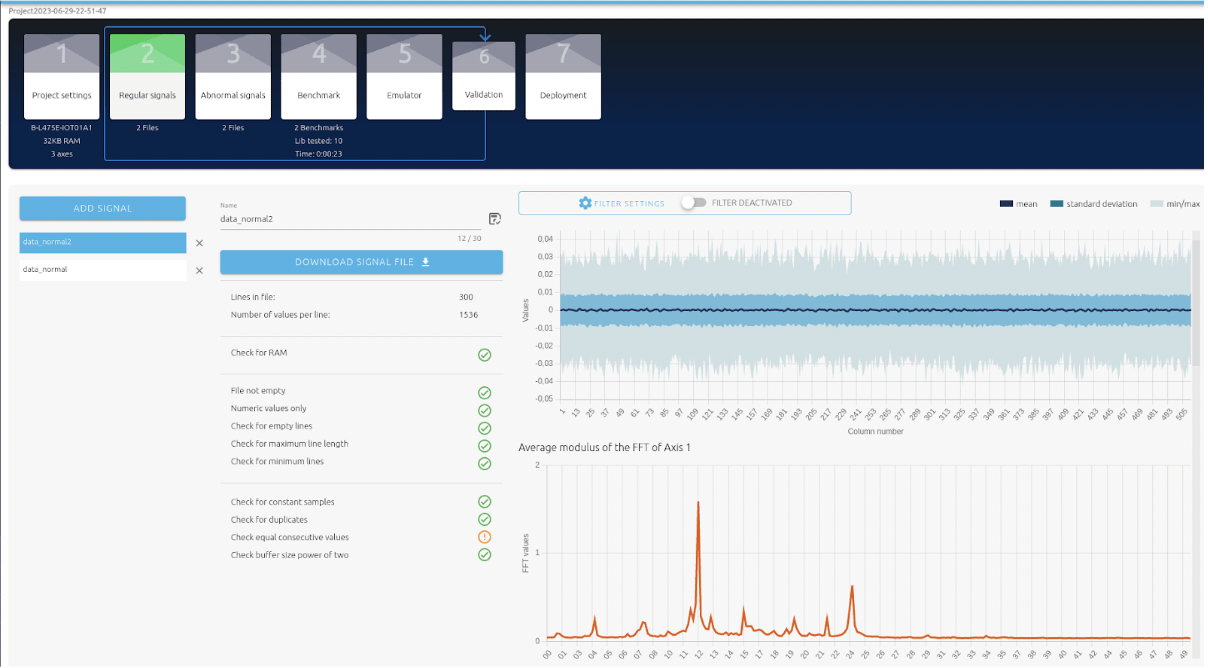
Acquisition de données dans le cas d’un fonctionnement normal pour les 3 vitesses du ventilateur. L’outil permet de visualiser et de nettoyer les données.
2. Benchmarking d’une librairie
Nous avons réalisé 2 datasets (normal et anormal) contenant 300 signaux d’exemples chacun.
A partir de ces données, l’outil a trouvé automatiquement la meilleure méthode de traitement de signal, le modèle de machine learning et les meilleurs hyperparamètres du modèle, tout en prenant en compte les ressources de la carte cible.
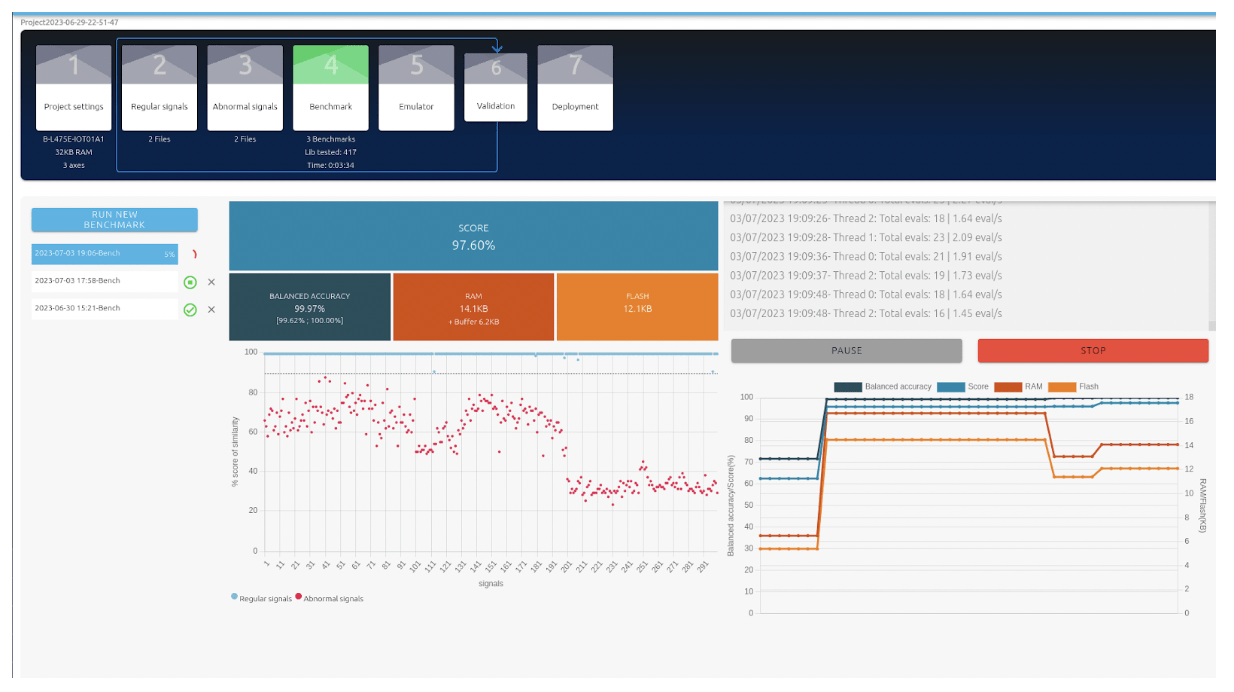
Résultat de l’Auto-ML : un score global (97,6%) basé sur plusieurs indicateurs donne une idée de la performance du modèle trouvé. La taille de l’algorithme en RAM et en Flash est donnée.
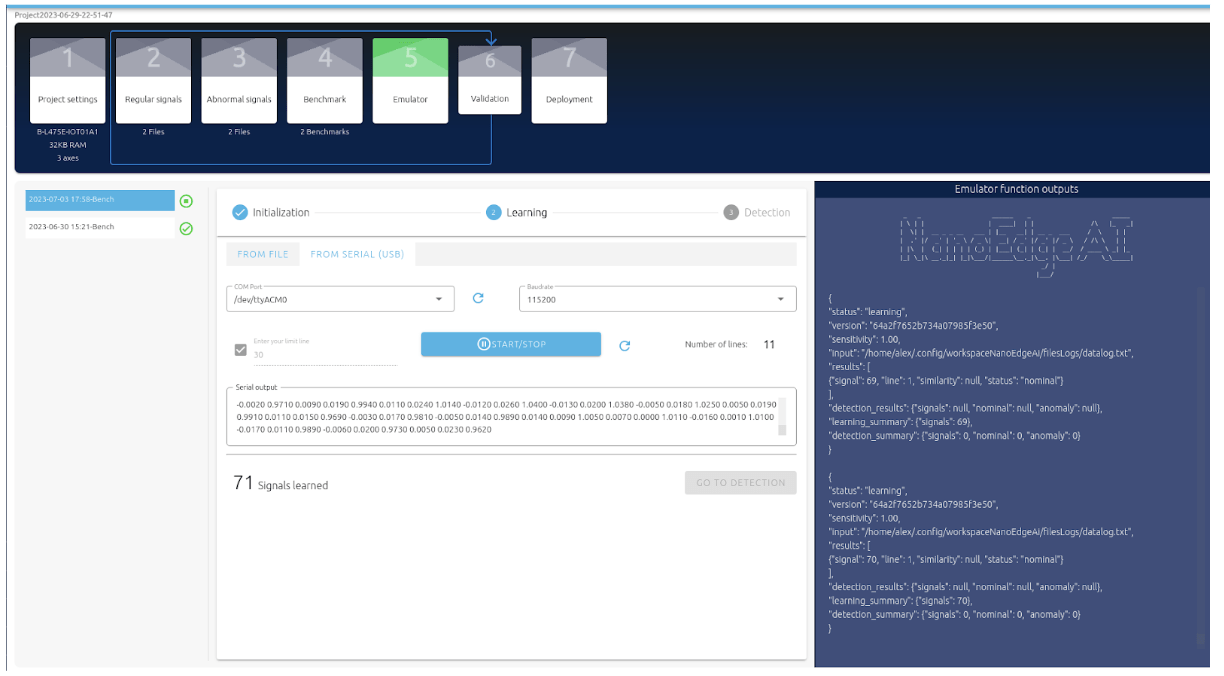
3. Émulation du modèle
Une fois entraîné, le modèle peut être lancé en temps réel sur son PC afin de valider que tous les cas normaux et anormaux sont détectés correctement.
Les données sont transmises par la carte électronique à travers une UART.
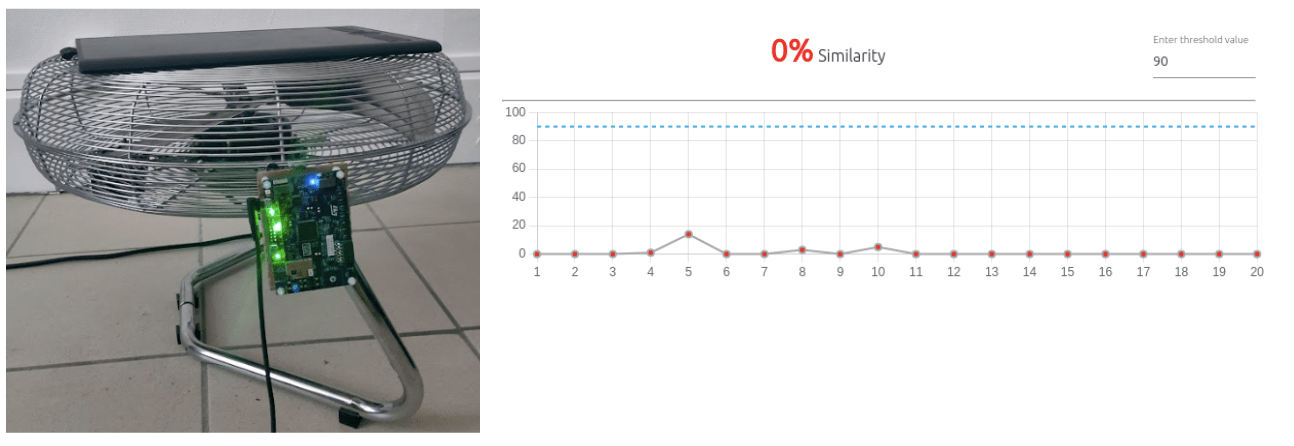
Dans le cas nominal (le ventilateur n’est pas obstrué), Nano edge permet de visualiser en temps réel la prédiction du modèle. Le cas nominal est bien détecté avec un score de similarité de 100 %.
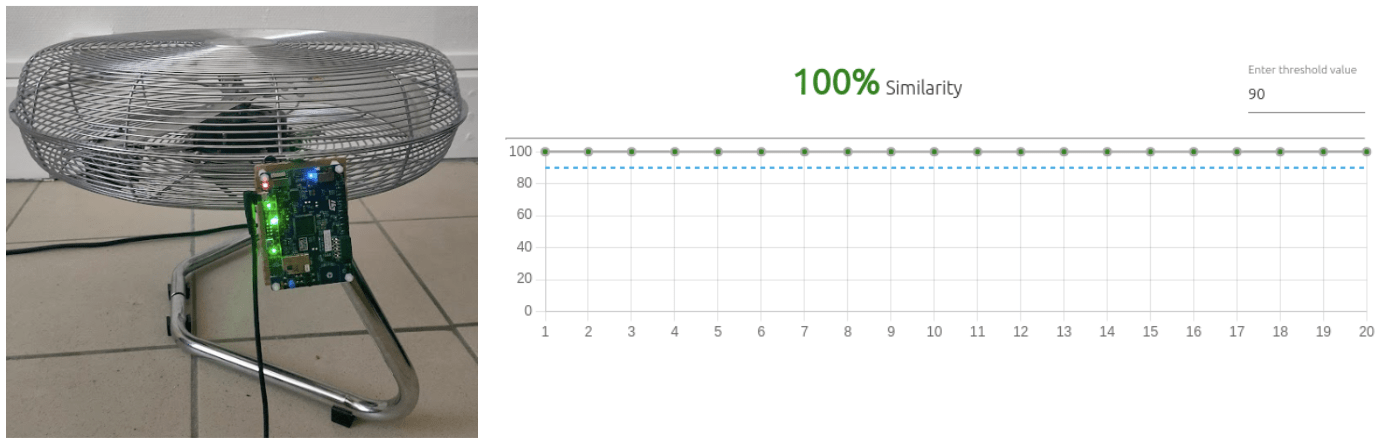
Lorsque l’on obstrue le ventilateur, l’anomalie est bien détectée : le score de similarité avec le cas nominal est de 0 %, comme on peut le voir sur le capteur ci-dessous.
On observe sur le graphique quelques variations du score dans le temps, et lors des phases de transitions d’un état à l’autre.
Il reste à exploiter soi-même la sortie du modèle, en fonction du contexte du cas d’utilisation.
4. Déploiement sur la cible de la librairie
Nanoedge AI Studio permet enfin de générer une librairie statique optimisée. L’étape finale consiste à intégrer cette librairie au projet STM32 en utilisant l’API générée.
Pour se donner une idée des résultats obtenus, nous avons réalisé une vidéo de démonstration, sur un autre projet similaire à celui-ci, dans lequel nous avons entraîné avec Nano Edge AI un modèle de classification pour détecter l’obstruction d’un ventilateur.
Ce modèle détecte aussi la vitesse du ventilateur (niveau de vitesse 1, 2 ou 3), et il se base sur les données d’un microphone (et non plus d’un accéléromètre).
La vitesse du ventilateur (speed 1/2/3) et l’obstruction sont bien détectées par le modèle. On peut constater des incohérences durant les phases de transitions entre 2 vitesses, ou lors des déplacements. Un lissage des inférences améliorerait considérablement ce défaut. Nous ne l’avons pas implémenté ici pour pouvoir visualiser la sortie brute du modèle.
5. Comparaison avec un algorithme non ML
Afin de se rendre compte de l’intérêt d’un algorithme de machine learning par rapport à un algorithme “classique”, nous avons également développé un algorithme de détection d’obstruction, sans utiliser de machine learning. L’algorithme repose uniquement sur l’application de seuils au volume du signal audio lissé.
Nous avons aussi incrusté les résultats de cet algorithme dans la vidéo précédente.
Bien que l’algorithme de seuils ne s’en sorte pas si mal, on constate que le modèle de ML est globalement plus robuste.
Notamment lorsque la carte équipée du micro est déplacée.
Le modèle de ML a été entraîné avec différentes positions de la carte et du ventilateur, lui permettant ainsi de ne pas être biaisé uniquement par le niveau sonore du son. Il est capable de se baser sur les caractéristiques du son propre au ventilateur, offrant ainsi une détection plus robuste que l’algorithme de seuils.
En conclusion, nous avons pu entrevoir dans ce chapitre que l’utilisation des outils d’AutoML engendrent un gain de temps considérable. En comparaison avec le développement complet du système, il ne reste qu’une poignée d’étapes de travail à réaliser.
Notons qu’il existe d’autres outils similaires à celui utilisé ici, comme eIQ de NXP par exemple.
« OK mais au final, combien de temps ça prend ? »
Nous estimons que pour un projet de classification de scène audio comme celui-ci, quelques semaines de développement d’un développeur suffisent pour arriver à un premier PoC, en partant de zéro.
L’automatisation a cependant un prix : la variété de scénarios couverts par ces outils est plus restreinte que ce qu’il est possible de faire lorsqu’on maîtrise le développement d’algorithmes de machine learning. De plus, même dans l’ensemble des scénarios couverts, la maîtrise de chacune des étapes du développement est assez faible, l’outil faisant le travail à notre place.
Pour regagner en maîtrise, une approche intermédiaire est possible, l’approche “Bring your own Model”.
Bring your own model (BYOM)
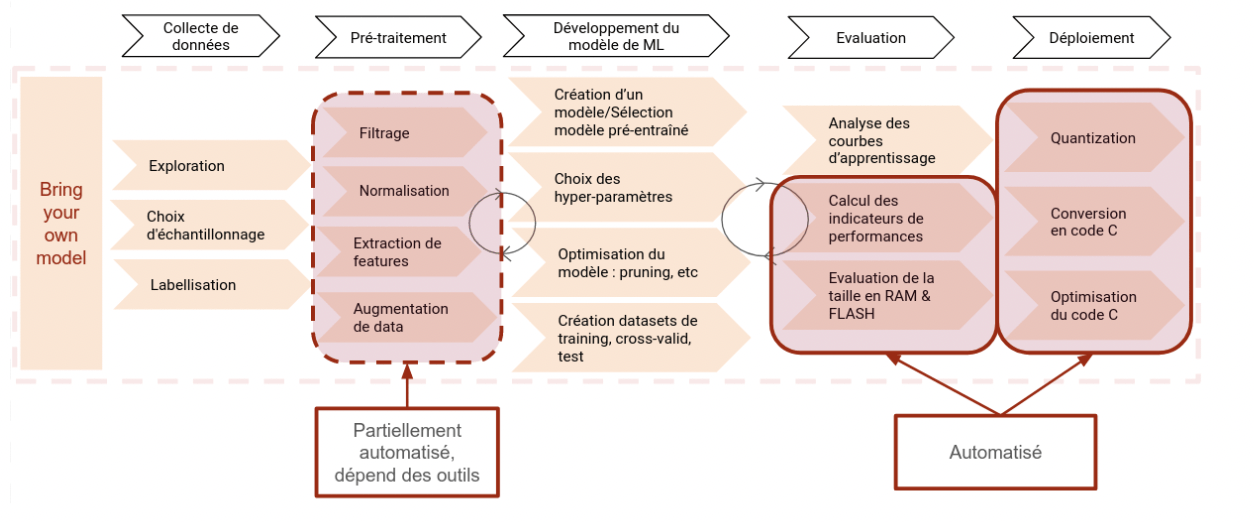
Cette approche est une intermédiaire entre les 2 précédentes. Certaines étapes du cycle de développement sont automatisées, mais le cœur du système, le développement du modèle de machine learning, est laissé à l’utilisateur.
Ce mode de développement donne la maîtrise du modèle utilisé, de la flexibilité, tout en gardant le gain de vitesse sur les étapes automatisées.
Le degré d’automatisation apporté varie en fonction des outils, mais généralement ce sont les parties Évaluation (Calcul des indicateurs de performances, Evaluation des la taille en RAM & Flash) et Déploiement (Quantization, Conversion en code C, Optimisation du code C pour la cible) qui sont automatisées. Enfin, pour les pré-traitements, des scripts peuvent être fournis pour différents cas d’usage.
Une bonne compréhension de ces traitements, ou mieux, des compétences ML et métier, sont nécessaires pour réaliser cette étape.
Nous avons suivi l’approche BYOM sur deux projets que nous vous présentons ici : un projet de détection d’événements audio, et un d’identification d’animaux de compagnie.
Détection d’événement audio
Ce projet d’évaluation consiste à détecter et classer des événements audio : le bruit d’une personne qui marche, de quelqu’un qui toque à une porte, d’une poignée qu’on actionne pour ouvrir la porte, etc. Nous exécutons l’algorithme de classification sur une carte d’évaluation équipée STM32U5 basé sur un Cortex-M33.
Ce projet est encore en développement mais, déjà, le premier retour que nous pouvons faire est que l’on constate vite le temps supplémentaire que nécessite une telle approche pour maîtriser chaque étape, et la complexité qu’il y a derrière chacune d’elles.
Pour ce projet, le pré-traitement, qui n’est qu’une des premières étapes, n’est pas trivial : il consiste à transformer un son, enregistré par un microphone, donc dans le domaine temporel, vers le domaine fréquentiel, pour pouvoir en extraire ses caractéristiques.
Plus précisément, le son est transformé en un mel-spectrogram : c’est un type de spectrogram particulier qui découpe le son en petites fenêtres, puis calcule la puissance pour chaque fréquence de ce signal, et le convertit sur une échelle logarithmique, comme représentée sur le schéma suivant.
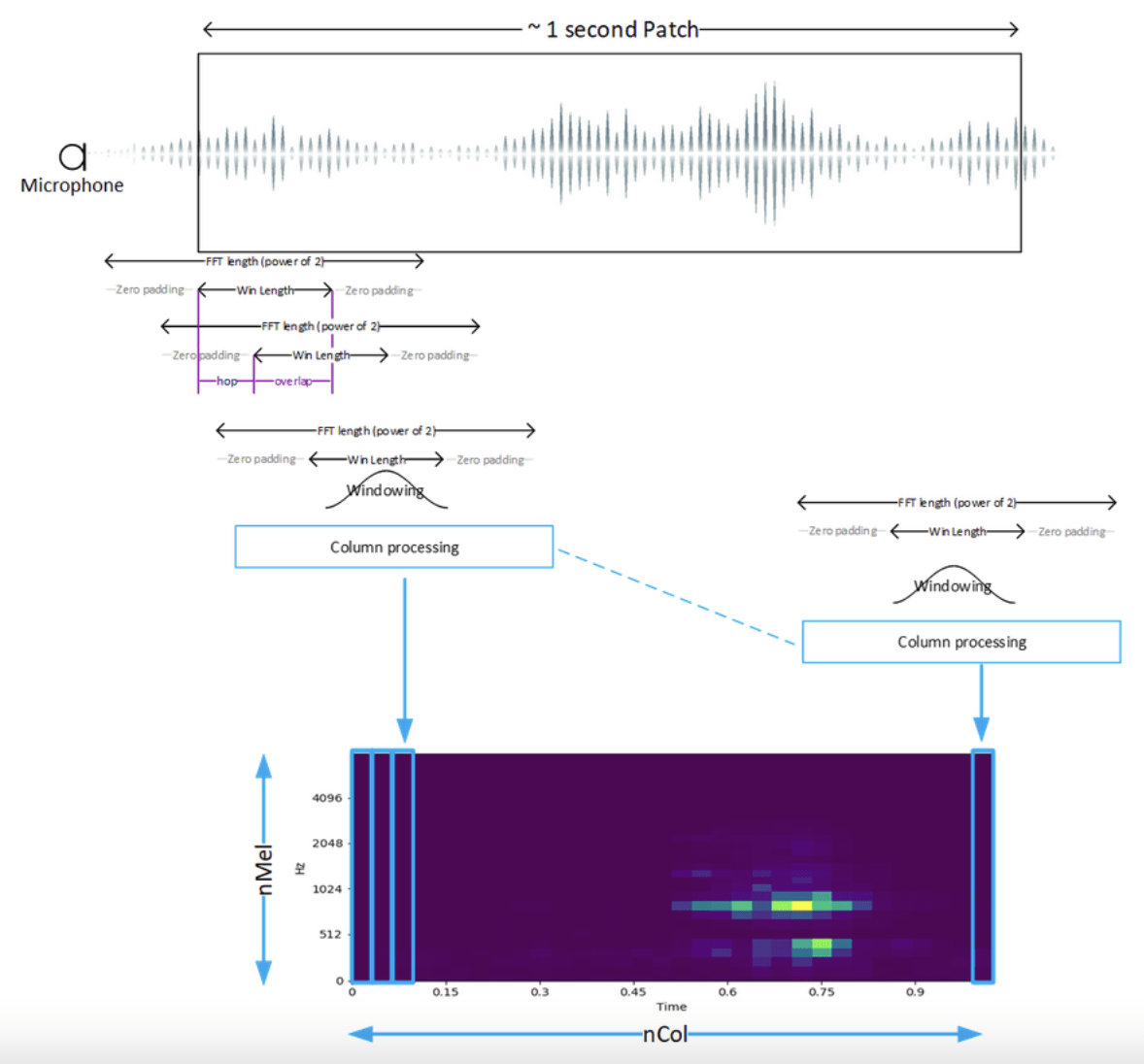
Schéma extrait du projet github STMicroelectronics Audio Event Detection
Cette étape nécessite de définir une dizaine de paramètres, tels que la taille de la fenêtre (win length), la longueur de saut entre 2 fenêtres (“hop”), les fréquences min et max contenu dans le signal, le nombre de colonne nCol et d’intervalles de fréquence que l’on veut garder (nMel), etc. Ces choix donnent une petite idée de l’expérience et des compétences nécessaires pour bien maîtriser cette partie relative au traitement du signal.
Quant aux étapes de développement du modèle de machine learning, nous avons choisi d’utiliser dans un premier temps un réseau de neurones existant (YAMNet), pour se concentrer sur la prise en main des outils, la customisation du dataset, et tester rapidement le code C généré.
STM32 CubeAI
Ce projet est développé avec STM32 CubeAI, qui est un ensemble d’outils utilisés pour l’approche BYOM :
- des scripts python de pré-traitement, d’entraînement, d’évaluation, pour des projets de plusieurs domaines différents
- une librairie et une plateforme en ligne pour le déploiement et le benchmarking du projet sur une ferme de cartes d’évaluations STM32
- des scripts .ipynb pour orchestrer toutes ces étapes, et pouvoir exécuter les scripts (l’entraînement en particulier) sur Google Colab par exemple :
Exemple de diagramme généré en fin d’entraînement par les scripts fournis :
Projet C et fichiers générés par les outils ST :
Voyons les résultats que l’on obtient :
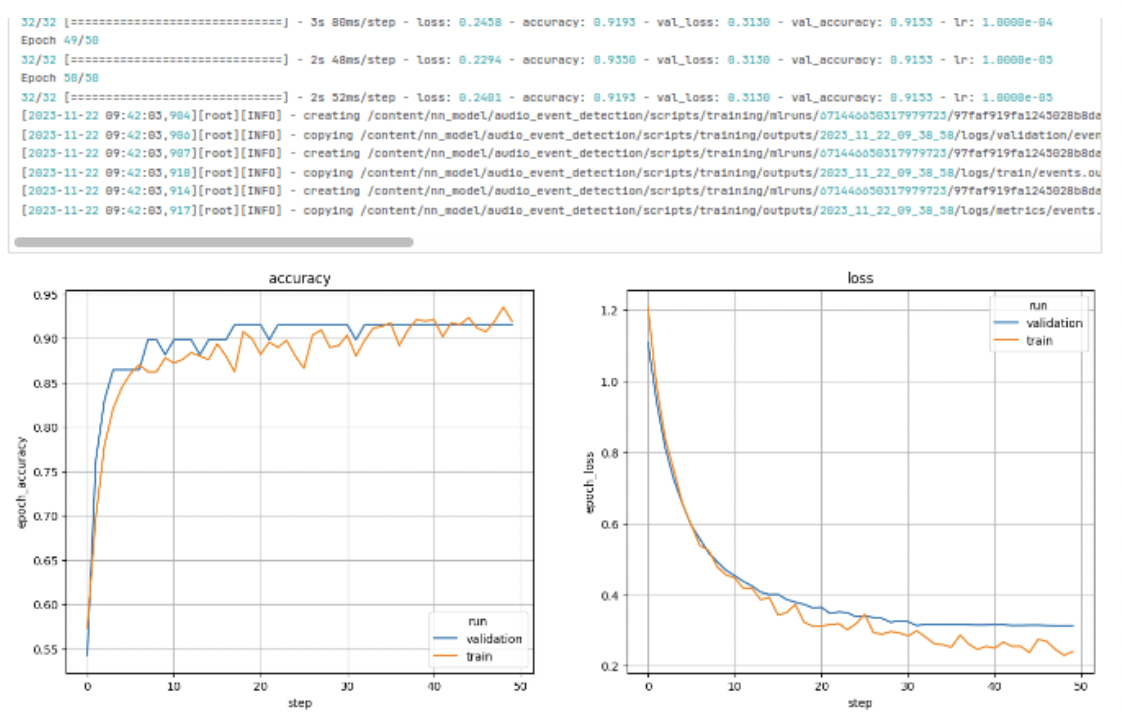
À l’heure de l’écriture de cet article, les résultats ne sont pas encore probants : parmi les 4 classes sur lesquelles le modèle a été entraîné, une seule est plutôt bien reconnue en run. De plus, il y a de nombreux faux positifs : des classes sont détectées alors qu’on produit des sons sans rapport.
Les indicateurs générés par les scripts fournis par ST, tels que la précision du modèle sur le dataset de validation, ou la matrice de confusion, laissent penser que les problèmes ne viennent pas du modèle ou de son entraînement, ni de son optimisation, mais d’ailleurs (dataset, données du capteur, etc.). Ils apportent de l’aide au débogage à venir.
Sans savoir encore combien de temps sera nécessaire pour arriver à un premier résultat satisfaisant (en laboratoire), on sent déjà que l’on est sur une échelle de temps différente qu’avec l’approche AutoML.
La maîtrise des étapes de pré-traitement, spécifique à l’audio, et de développement du modèle, qui nécessitera probablement des optimisations si l’on souhaite détecter des sons brefs ou se ressemblant, peut probablement prendre 2 à 4 fois plus de temps que la méthode AutoML.
Identification d’animaux de compagnie
Ce projet commercial a pour objectif d’identifier un animal de compagnie à l’aide d’une caméra. C’est-à-dire de détecter lequel de vos chiens ou chats est face à la caméra, et non pas simplement de détecter si c’est un chien ou un chat.
La partie embarquée réalisera la détection simple (y-a-t-il un chien devant la caméra ?) tandis que l’identification sera réalisée ensuite dans le cloud. C’est un bel exemple de complémentarité embarqué – cloud.
L’algorithme de détection doit s’exécuter sur un ESP32S3.
TensorFlow Light for Microcontrollers
Pour ce projet en cours de développement, nous avons à notre disposition un jeu de données fourni par notre client. Le pré-traitement pour les images issues de notre caméra étant relativement standard, nous nous sommes concentrés sur le développement du modèle de réseau de neurones, réalisé avec TensorFlow et sa surcouche Keras.
Nous avons ensuite utilisé TensorFlow Lite for Microcontrollers pour la conversion et l’optimisation du modèle en code C++.
Nous sommes partis d’un modèle pré-existant, puis nous avons réalisé un élagage de couches pour réduire la taille et le besoin en RAM du modèle. Afin d’améliorer la robustesse et la performance, nous avons cherché les meilleures combinaisons d’hyper-paramètres pour notre besoin et jeux de données.
Après quelques semaines de travail, les résultats sont satisfaisants (seulement 5% de faux négatif), mais toujours améliorable à travers les données d’entrées.
Le temps nécessaire pour le développement du modèle sur ce projet n’est somme toute pas très important. Le projet dans son ensemble sera beaucoup plus long : l’étape de collecte de données pour obtenir un dataset important et de qualité a pris du temps.
L’intégration complète de l’algorithme de machine learning, avec les contraintes imposées par le reste du firmware (en cours de développement, en parallèle), reste encore à réaliser.
Enfin, les images issues du terrain, une fois le produit déployé dans des environnements non contrôlés, seront-elles suffisamment proches du dataset d’entraînement ? Combien de réitérations seront nécessaires pour atteindre un résultat satisfaisant ? L’avenir nous le dira.
Pour aller plus loin
Dans cet article, nous nous sommes concentrés principalement sur les outils STMicroelectronics, mais bien d’autres acteurs proposent des solutions équivalentes.
On pense notamment aux solutions NXP eIQ, à Edge Impulse, Qeexo, Deeplite, ou encore SensiML.

Côté hardware, de plus en plus de solutions optimisées pour le machine learning arrivent sur le marché, pour accélérer le temps d’inférence, et pouvoir exécuter des tâches de plus en plus complexes.
Certains MCU sont dotés d’un accélérateur interne qui leur permet d’être plus efficaces, par exemple l’ESP32-S3 avec son set d’instruction étendu.
Pour plus de puissance encore, on peut se tourner vers les hardwares spécialisés les Neural Processing Unit (NPU), ou puce d’accélération de réseaux de neurones [Perceive, Syntiant, etc.].
Les prévisions d’investissement mondiale dans le domaine de l’IA embarquée confirment cette offre florissante : ils devraient doubler tous les 2 ans dans les années à venir (Source : Morgan Stanley Research).
Enfin, si vous souhaitez en savoir plus sur l’ensemble des industries qui adoptent l’IA, les différents types d’algorithmes couramment utilisés, les challenges actuels et le futur de l’IA embarqué, nous vous recommandons la lecture du rapport 2023 Edge AI Technology Report réalisé par Wevolver en partenariat avec la Fondation TinyML. Cet état de l’art de 116 pages couvre de nombreux autres sujets, avec un angle de vue plus large sur l’Edge AI, incluant des plateformes et des frameworks plus puissants tels que NVIDIA Jetson ou PyTorch Mobile

L’IA dans l’embarqué : choisissez, explorez, innovez !
Félicitations à vous si vous êtes arrivé au bout de cet article (!), que nous avions imaginé court au départ… Le domaine du machine learning est vaste, et la surcouche “embarquée” n’allège rien.
Ces 2 domaines conjugués offrent des opportunités passionnantes pour l’innovation, transformant la manière dont les systèmes autonomes interagissent avec leur environnement.
Lorsque vient le moment de choisir la plateforme pour donner vie à vos projets de machine learning embarqué, vous avez l’embarras du choix.
Des options variées, telles que ST Microelectronics, Espressif, Edge Impulse, eIQ, et d’autres, s’offrent à vous. Le choix de la plateforme et de l’approche de développement dépend de vos besoins spécifiques, du niveau d’expertise de votre équipe de développement, et du budget que vous êtes prêt à consacrer en licence (certains outils sont payants, d’autres gratuits).
Et là, bonne nouvelle ! Si vous vous sentez un peu perdu parmi toutes ces possibilités, ne vous inquiétez pas.
Chez Rtone, nous sommes là pour vous aider.
Forts de nos premières expériences, nous pouvons vous accompagner sur vos projets.
Ah, et n’oublions pas le matériel spécialisé ! Si vos projets demandent beaucoup de puissance pour les inférences, l’utilisation de hardware dédié peut être la solution magique pour booster les performances.
Que vous soyez un CTO intrépide, un CEO visionnaire, un porteur de projet plein d’ambition, ou un développeur passionné, explorer les merveilles du machine learning embarqué peut ouvrir de nouvelles perspectives et vous propulser vers des avancées significatives dans une multitude de domaines.
Alors, partons ensemble à la découverte de ces possibilités infinies ! 🚀
Nous contacter









