À l’occasion du salon Embedded World de Nuremberg, qui se tient du 9 au 11 avril 2024, nous proposons une nouvelle démo issue de nos travaux en machine learning embarqué sur le mur partenaire du stand de STMicroelectronics.
À l’occasion du salon Embedded World de Nuremberg, qui se tient du 9 au 11 avril 2024, nous proposons une nouvelle démo issue de nos travaux en machine learning embarqué sur le mur partenaire du stand de STMicroelectronics.

À l’occasion de l’exposition Embedded World à Nuremberg, qui s’est déroulé du 9 au 11 avril 2024, nous avons proposé une démonstration de machine learning embarquée pour le mur des partenaires du stand STMicroelectronics. Cette démonstration résulte de notre travail sur plusieurs mois.
Rtone développe ses compétences en machine learning embarqué depuis un an maintenant. En tant qu’intégrateurs spécialisés dans le domaine de l’IoT, il est important pour nous d’avoir le plus large éventail possible de connaissances sur les cas d’application potentiels de l’apprentissage machine embarqué et les solutions techniques disponibles auprès des différents acteurs du marché.
Nous nous sommes naturellement tournés vers STMicroelectronics, en particulier vers sa suite Nano EdgeAI Studio, qui promet une mise en œuvre rapide et guidée d’algorithmes prêts à l’emploi pour le déploiement sans connaissances avancées en data science.
Vous trouverez dans cet article mes détails de nos travaux et les premiers résultats que nous avions présens lors de notre meet up en fin 2023.
L’objectif de cette démo est de montrer un cas pratique d’apprentissage sur le MCU (on device learning) pour de la détection de défauts. L’intérêt est de s’adapter précisément aux variations de l’environnement dans lequel fonctionne le dispositif à surveiller. Ici, nous faisons coexister un petit moteur et une pompe à air, sachant que les vibrations générées par ces deux éléments perturberaient et compliqueraient la détection classique basée sur des seuils de mesure.
L’algorithme de machine learning entraîné directement sur le MCU permet de déterminer précisément les conditions de fonctionnement normales du système et de détecter toutes anomalies, qu’elles proviennent du fonctionnement du moteur ou de la pompe. Vous trouverez ci-dessous une vidéo de la démo ainsi qu’une description technique détaillée du travail réalisé.
Cette démo met en œuvre un modèle d’apprentissage machine pour détecter les anomalies vibratoires à partir d’un accéléromètre 3D.
Les vibrations sont générées par 2 types d’actionneurs :
La démonstration commence par le démarrage d’un seul actionneur, suivi de l’apprentissage de cette configuration spécifique.
L’apprentissage se fait en temps réel sur le MCU et comprend 50 signaux.
La manipulation du dispositif en marche conduit à la création d’anomalies qui sont détectées.
Un nouvel apprentissage peut être réalisé pour renforcer les données d’apprentissage du modèle existant.
Lorsque le deuxième actionneur est activé, il génère des perturbations vibratoires qui déclenchent également la détection d’anomalies.
Un nouvel apprentissage permet d’apprendre cette nouvelle configuration, avec les 2 actionneurs.
La manipulation de l’un des 2 dispositifs conduit à la détection d’anomalies.
Carte : STEVAL-STWINKT1B (pour l’entraînement et l’inférence)
Capteur : Accéléromètre 3D ISM330DHCX
Fréquence d’échantillonnage : 3,3 KHz
Résolution : 2G
Nombre d’axes : 3
Nombre de valeurs par signal : 3*1024
Nombre de signaux par sous-ensemble de données : 2*300
Nombre de sous-ensembles de données : 10
Nombre total de signaux : 6000
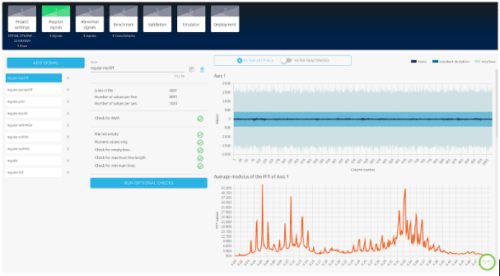
Vue des données de signal normalisées de NanoEdge AI Studio
Initialement, nous avons choisi des paramètres visant à maximiser les données obtenues, cela nous a permis d’avoir plus de précision et prendre de meilleures décisions sur les paramètres finaux.
Nous configurons l’accéléromètre à une fréquence d’échantillonnage maximale de 6667 Hz. Les signaux ont une durée de 0,5 seconde pour assurer la capture adéquate des éléments physiques nécessaires à la détection d’anomalies.
Nous affichons la valeur moyenne de nos échantillons de signal.
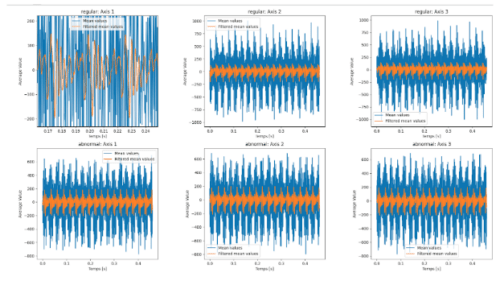
Nous observons 17 éléments physiques, mais nous pouvons les réduire à environ dix, ce qui entraîne un raccourcissement de la durée de nos signaux à 0,3 seconde.
Une transformée de Fourier est ensuite appliquée aux échantillons de signal, suivie du calcul de la moyenne des valeurs absolues du résultat de l’algorithme de transformation de Fourrier.
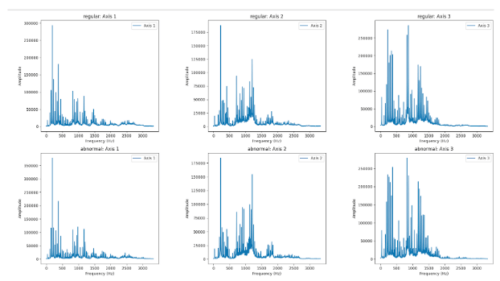
Nous observons des fréquences avec une amplitude significative en dessous de 1,6 kHz. Par conséquent, la fréquence d’échantillonnage de l’accéléromètre est ajustée à 3,3 kHz.
Enfin, nous choisissons 1024 valeurs par axe et par signal. Chaque signal correspondant à une durée de 0,3 seconde à une fréquence d’échantillonnage de 3333 Hz.
Nous sélectionnons nos sous-ensembles afin de couvrir tous les cas anormaux dans 3 situations différentes (moteur seul, pompe seule, moteur et pompe).
Les cas anormaux sont maintenus relativement simples afin de trouver un modèle avec une bonne précision et ne nécessitant pas trop d’itérations d’apprentissage.
| Cas normal | Cas anormal |
|---|---|
| Moteur sans balourd | Moteur OFF |
| Moteur sans balourd | Balourd à 50% |
| Moteur sans balourd | Balourd à 100% |
| Pompe valve ouverte | Pompe OFF |
| Pompe valve ouverte | Valve fermée à 75% |
| Pompe valve ouverte | Valve fermée à 100% |
| Moteur sans balourd and pompe valve ouverte | Balourd à 50% |
| Moteur sans balourd and pompe valve ouverte | Balourd à 100% |
| Moteur sans balourd and pompe valve ouverte | Valve fermée à 75% |
| Moteur sans balourd and pompe valve ouverte | Valve fermée à 100% |
NanoEdge AI Studio est une solution d’auto-ML qui trouve automatiquement la bibliothèque d’apprentissage machine la plus adaptée à nos données.
Une bibliothèque se compose d’un algorithme de traitement du signal, d’un modèle de machine learning et d’hyperparamètres (paramètres utilisés pour l’entraînement du modèle).
Des benchmarks entre les différentes bibliothèques présélection sont effectués pour obtenir les meilleures performances en termes de précision et de ressources mémoire.
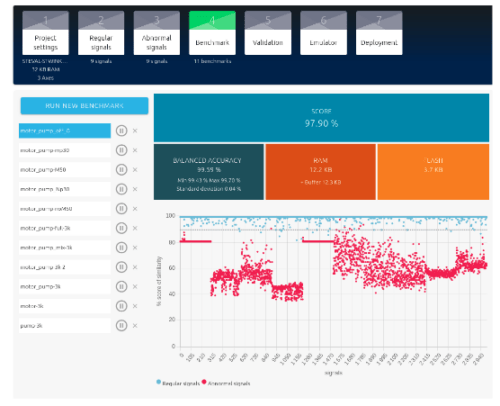
Cette étape doit être réalisée de manière méthodique en ajoutant les sous-ensembles de données un par un. Cela permet d’identifier plus facilement les données qui dégradent les performances du modèle.
Mémoire RAM : 24.5 KB
Mémoire Flash : 3.7 KB
Temps d’inférence : 7 ms
Temps d’acquisition du signal : 300ms
Consommation moyenne du MCU : 37 mA
Axes :
Le nombre d’axes fait référence au nombre d’entrées utilisées par le modèle, dans notre cas, nous avons 3 axes correspondant aux coordonnées x, y, z de l’accéléromètre.
Échantillon :
Un échantillon correspond aux données instantanées de l’accéléromètre. Pour un échantillon, nous avons une valeur par axe, donc un total de 3 valeurs.
Signal:
Un signal contient des échantillons de l’accéléromètre sur une séquence temporelle contenant un phénomène physique. Ce sont les données de ce phénomène physique qui sont exploitées par le modèle pour la détection d’anomalies.
Sous-ensemble de données :
Un sous-ensemble de données rassemble les signaux des situations normales et anormales pour un cas d’utilisation spécifique. Par exemple, un sous-ensemble de données peut représenter une anomalie vibratoire générée par la pompe et un autre pour une anomalie générée par le moteur.
Ensemble de données :
L’ensemble de données rassemble les données de tous les sous-ensembles de données. Ces données sont utilisées pour entraîner le modèle.
Un peu de lecture
Des articles, des podcasts, des webinars… et surtout des conseils pratiques ! En bref, une collection de ressources pour mener à bien votre projet.








